
Blog
About
Code
Publications
Consulting
Archive
Current page
Introduction
Are collections worth the effort?
Method
Results
Conclusions
Performance gain for combining multiple GL objects into a single buffer
Rendering a set of 100.000 vertices with OpenGL is very fast. However, rendering 100 sets of 1000 vertices is significantly slower (even though the total number of vertices is the same). Therefore, in visualization libraries, collecting multiple objects in a single buffer can help increase performance. In this post I try to get a grip on how much this really matters. Result: it depends.

Image by Omega via Flicker (CC BY-SA 2.0)
Introduction
OpenGL (and WebGL for the browser) is the obvious choice for making fast visualizations. It is capable of drawing tens of millions of points while maintaining a framerate that is sufficient for interactive use. Even without a beefy GPU, the intel integrated graphics is nowadays sufficiently powerful to e.g. render volumes interactively.
In a visualization system there are sometimes many (small) objects that need to be visualized. The program iterates over these objects and draws them one by one, which adds overhead and thus reduces performance.
This is why we are working on implementing a technique in Vispy that allows multiple objects to share buffers, and be drawn using only one GL call. Nicolas Rougier, who has been doing most of the work in this direction, calls this technique "collections".
Are collections worth the effort?
Recently, I was implementing a WebGL-based plotting system in JavaScript for the Bokeh project, and I (obviously) wanted good performance, so I thought about collections. However, implementing collections also adds complexity to the code, and this caused me to wonder how much we really need it.
The overhead consists of (at least) three sources:
- There is a for loop in the code. The significance of this depends on the programming language (and its implementation). It's pretty bad for an interpreted language like Python. For most JavaScript implementations it should matter much less.
- There is an overhead in the OpenGL API calls. In Python the calls go via ctypes. On the browser its more direct, but on Windows they go via the Angle library to translate the calls to DirectX.
- There is an overhead in the driver. Swapping the current GL program takes time.
To what extend each source degrades performance is not very clear. The only way to find out, of course, is to try!
Method
I wrote two simple scripts (one in Python and one in JavaScript) that draw M lines of N points, and measure the FPS. The Python code relies on vispy.gloo, and the JS code on a variant of gloo implemented in JS. The code can be obtained from its github repo.
The scripts were run multiple times, while the M parameter was varied from 1 to 500, increasing the number of GL programs (thereby simulating the number of objects being drawn) while keeping the total number of vertices the same.
This was done on a number of platforms and browsers. Most experiments were performed with a total number of points of 100.000, and a smaller experiment was done with 1 million points to validate if the trends hold up.
In a second experiment, the same measurement is performed, except that for all M interations, we use the same GL program, attaching the i-th buffer to it right before drawing.
All experiments were run on a laptop with an Intel i7-4710HQ CPU (2.50GHz) and a GeForce GTX 870M GPU.
Results
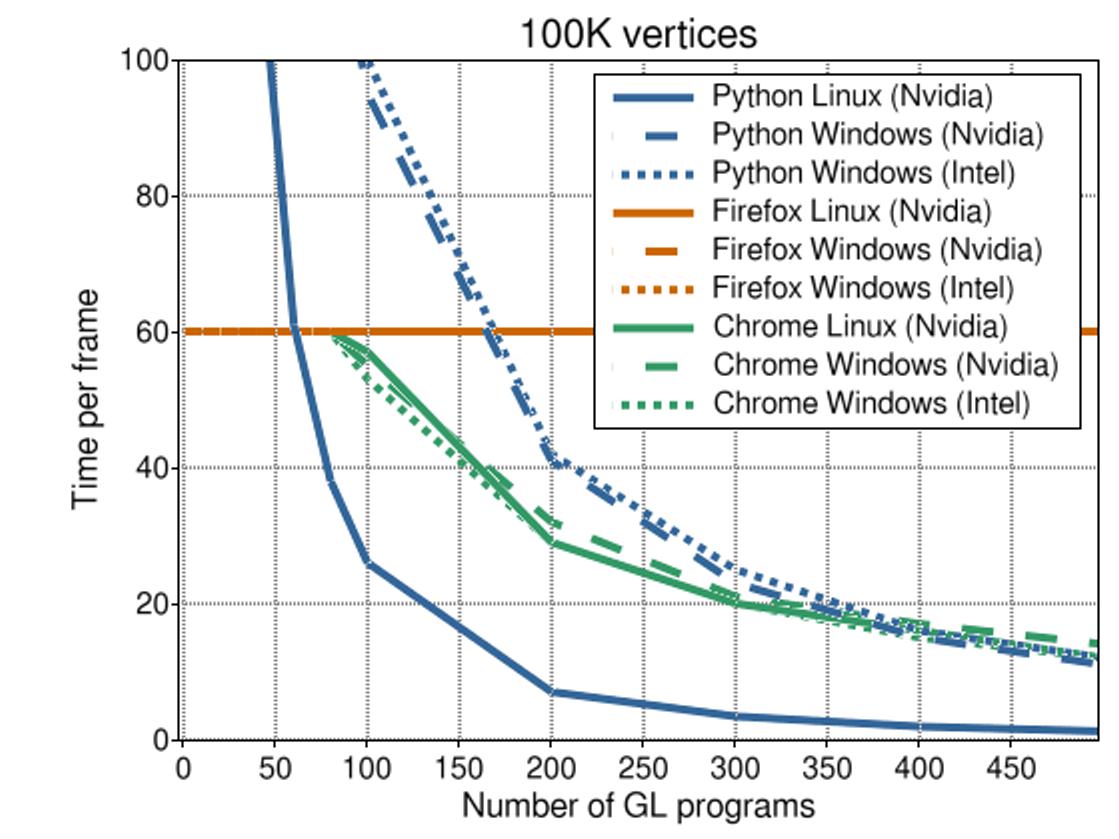
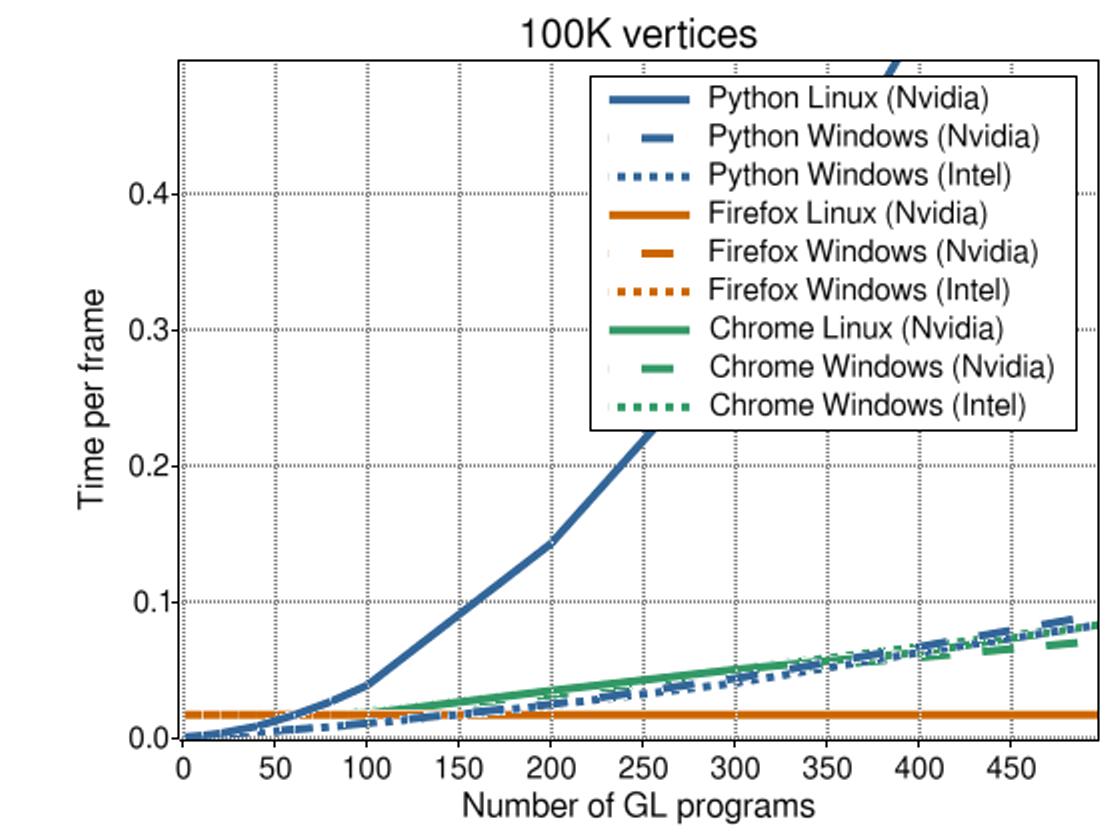
The illustration above clearly shows that Python suffers the most as the number of objects is increased, the FPS dropping below 10 at about 180 objects on Linux. Interestingly, on Windows things are much better (though the curve is equally steep). This can probably be explained by the fact the GL drivers are better developed on Windows (as any gamer can tell you).
We can see how in the browser the framerate is limited to 60 FPS. This is common practice for applications but explicitly turned off in Vispy.
For Firefox, the framerate stays at a steady 60 FPS, even for Intel graphics. Wait what? I am not sure how to explain that ... This looks a bit like a vsync thing.
For Chrome, the downward trend is less steep than it is for Python. This can be explained by the fact that the overhead for iterating over the objects is faster (because JavaScript is much faster). What's left is mostly the overhead of the GPU driver itself.
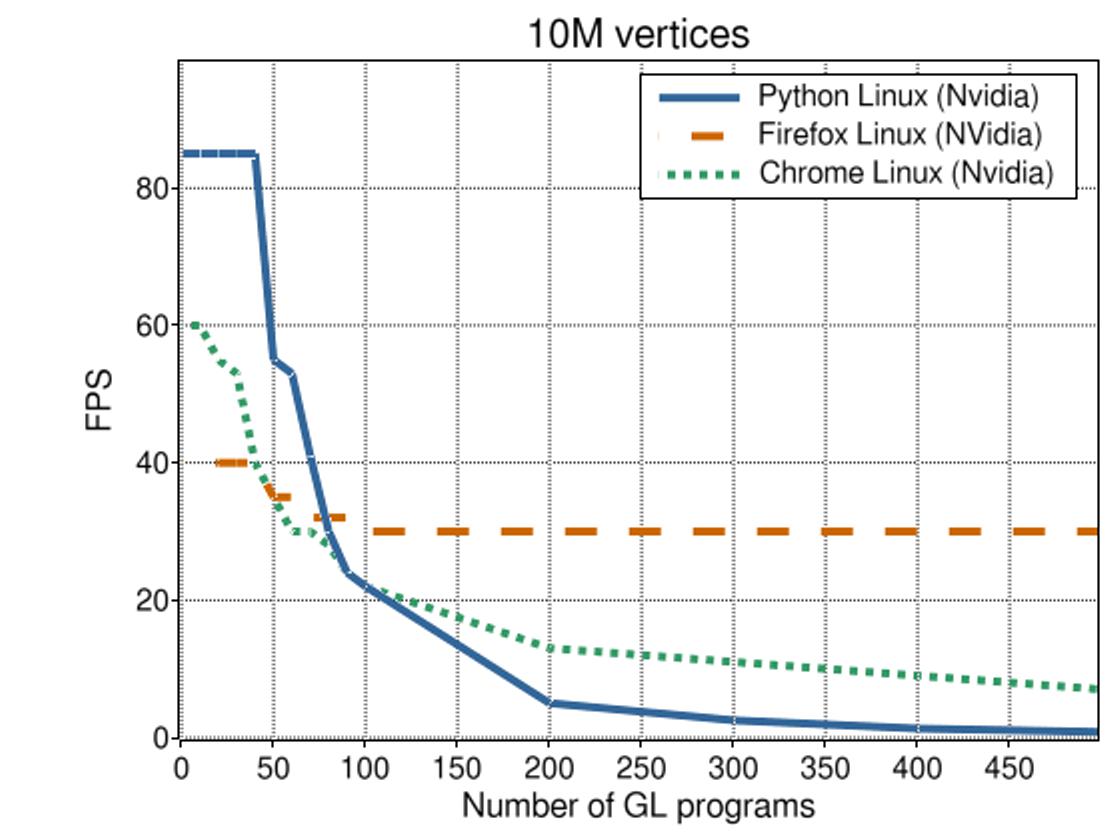
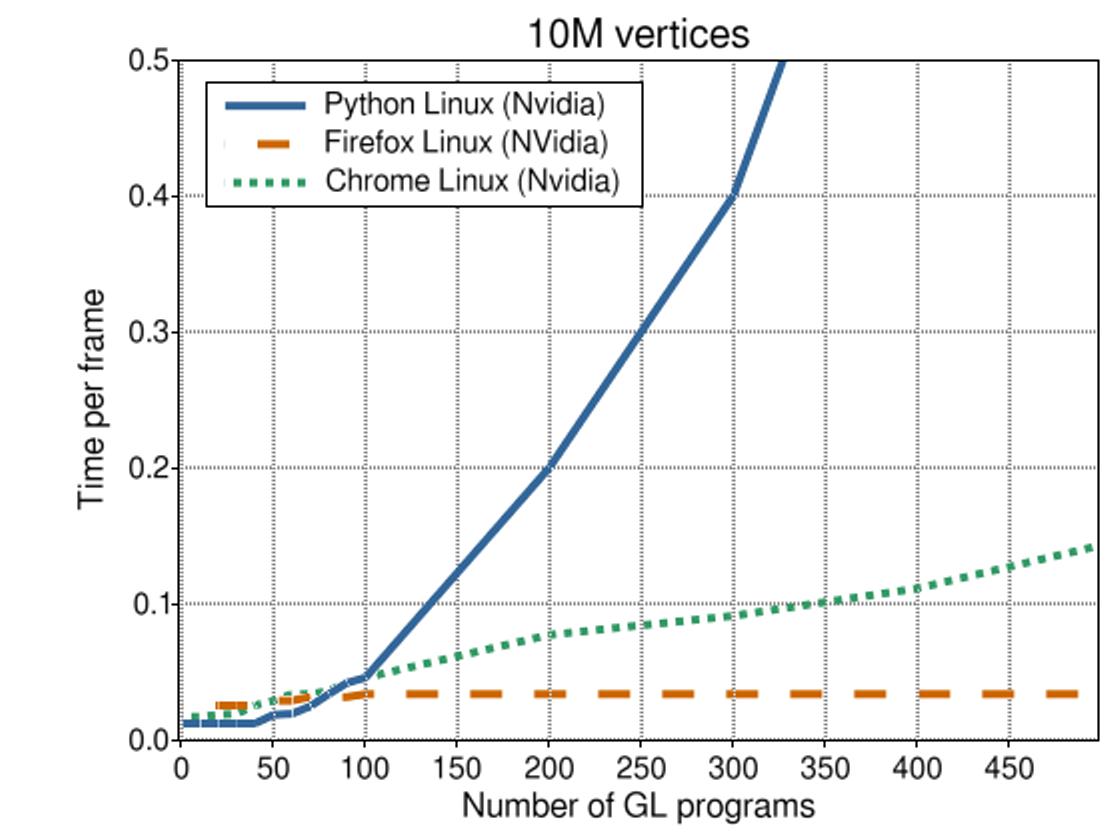
This illustration shows the same trends when we render more vertices. However, they are less strong; The cost of drawing one object is now higher, causing the relative cost of the overhead to be smaller. In other words, for more complex a visualizations, the overhead of rendering multiple objects is smaller.
We also see that Firefox has a small dip at first, but then remains steady at 30 FPS. Not sure what this means, but I think we should ignore the Firefox measurements.
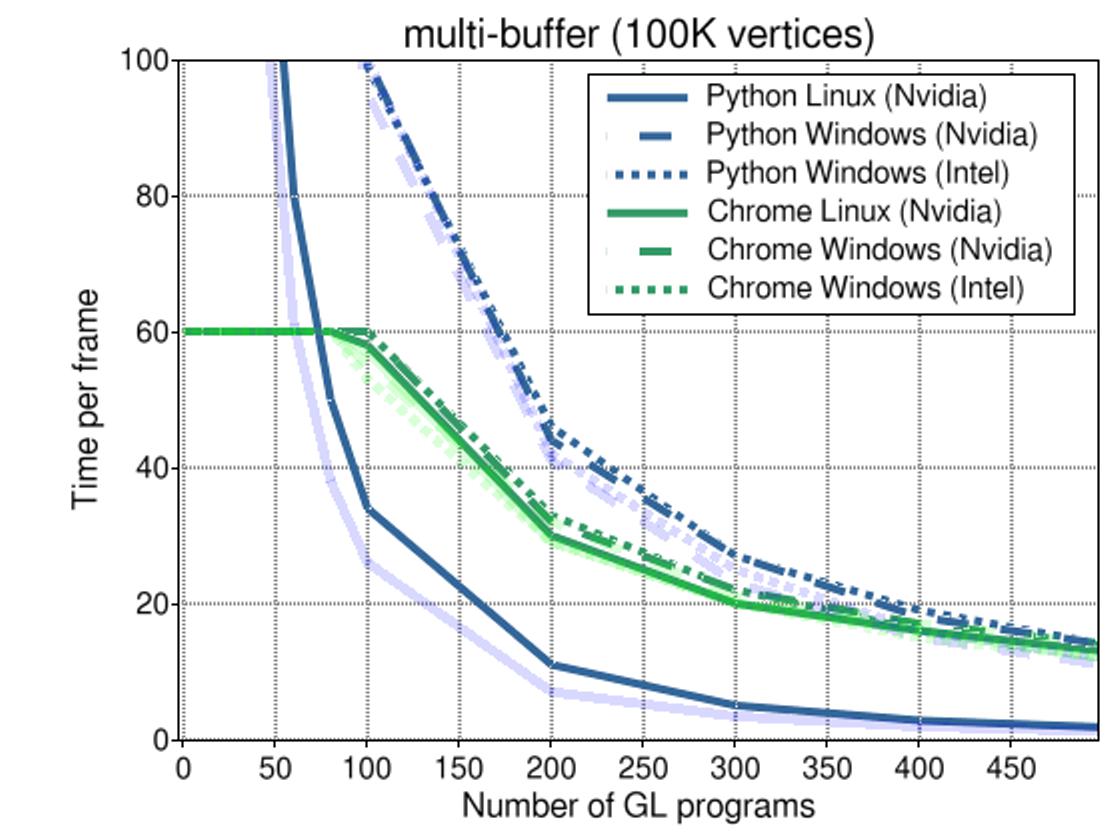
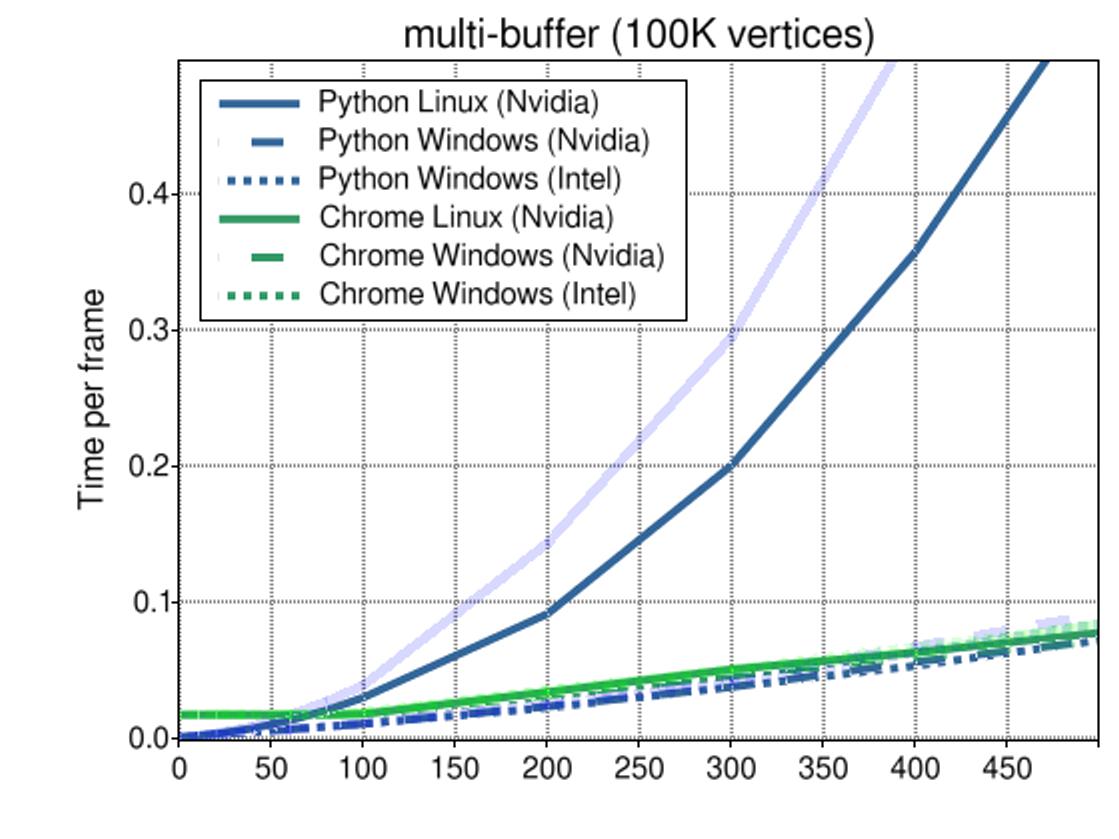
This illustration shows that by using multiple buffers against the same GL program, the performance can be increased, though not by a lot.
Conclusions
It is clear that drawing M objects of N points is more costly than drawing MxN points in one go. The effects are larger in Python than they are in JavaScript, which can be explained by the fact that JS is faster.
The relative importance of the overhead also depends on the complexity of the visualization.
Finally, in this experiment we did not take into account the costs for making collections happen: collections requires code to pack multiple objects together. Typically, right before each draw, some code will be run for each object, for example to prepare the collection, or to ensure that it is up to date. How high this cost really is depends on how efficiently the system is able to integrate the idea of collections. And of course, implementing collections adds a maintenance burden.
From this we can state that collections are probably worth the effort when implementing fast visualization of multiple simple objects in Python. When implementing complex visualizations in JavaScript, this is much less the case.
A marginal performance gain can be achieved by reusing the GL program object, which will usually be easier to implement than sharing both program and buffers.
Finally, these benchmarks were performed on just one machine, and different results might be found on different hardware. Nevertheless, I believe the trends should hold up.